While people with linguistic background might be familiar with the term “Lemmatization” or “Lemmatize“, for the rest of us, it is not one of the most common terms we use in our every day life.
What is Lemmatization?
Lemmatization is closely related to stemming. In linguistics, it is the process of grouping together the different inflected forms of a word so they can be analyzed as a single item. Putting an example to the definition, “computers” is an inflected form of “computer”, the same logic as “dogs” being an inflected form of “dog”.
In simple words, I would explain lemmatization as returning different forms of a single word to its root form. Given that both examples that I gave are nouns, do not be confused that it is only applicable to nouns. Lemmatization works the same way for adjectives, action verbs, all the same. Such as:
- Constructing – (Lemmatization) -> Construct
- Extracts – (Lemmatization) -> Extract
- Singing – (Lemmatization) -> Sing
It may seem pretty straightforward at a glance. But confusion sets in when dealing with words like “Worker” and “Speaker”. “Worker” is not an inflected form of “Work“, neither is “Speaker” an inflected form of “Speak”. That is because “Speaker” (noun), is someone who talks (especially someone who delivers a public speech or someone especially garrulous), while “Speak” (verb) is the act of giving a speech. In instances such as the above example, even though the word seemingly takes on the basic root of a certain word, it should not be confused as the inflected term.
The simple rule is to remember that Lemmatization changes the verb form, while keeping the meaning of the word the same.
Lemmatizer API
Now that you’ve learned the basic concept of Lemmatization, try it out at Twinword Lemmatizer API demo page. Simply copy and paste in text extracts and let the Lemmatizer API return the lemmatized form of the words!
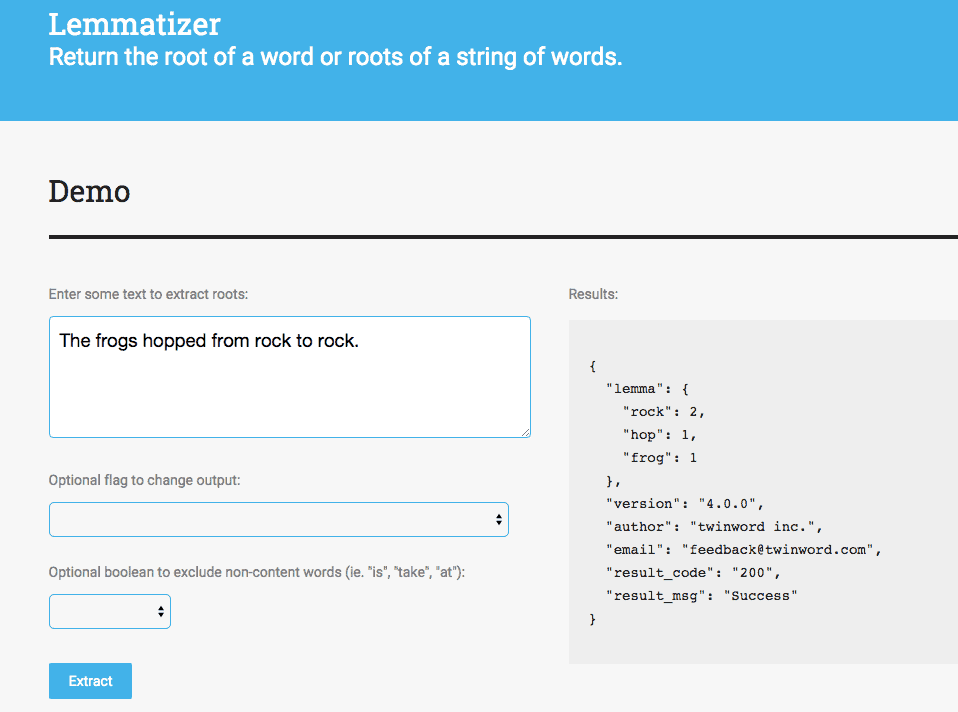
Now, let’s focus more on the actual application of the Lemmatizer API.

English is one of the most widely used language in the world, having over 335 millions native speakers. (Source: Ethnologue, 2014) Taking into consideration this number only represents people speaking English as a first language, the actual number of English speakers (including people adopting English as a second/third language) far exceeds the figure mentioned above.
Depending on where you are from, the English might be a little different. Accent and slang aside, there are times when a word can have two different spelling; the British English or the American English way of spelling. Listing a few examples:
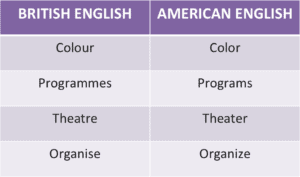
How can we program the computer to recognize the same word with different spellings? The solution is the integration of the Lemmatizer API. Not just simply returning words to their root form, the Lemmatizer API also recognizes “Colour” = “Color”, “Organise” = “Organize”.
Uses Of Lemmatizer API
- Search Engines/Tools/Extension
Lemmatization is very useful for search software. For example searching for “big dogs” will trigger the search for “big dog”, “Theatre in San Francisco” will trigger the search for “Theater in San Francisco” and etc. Not just search engines, search tools are also commonly built with the same functionality.
- Educational Software/Applications
The Lemmatizer API is also applicable for English learning software or applications. It could be for building an app that requires the learner to identify and recognize the different forms of a same word and match them to the root form. For instance, recognizing “goes”, “gone” and “went” as inflected forms of the root verb “go”.
- Text Analysis
With the rising importance of text analysis for businesses, developing a comprehensive text analytical tool is essential to make the former possible. Check out the demo page of our Lemmatizer API to get what I mean!
PS: Did you know that “is”, “was” and “were” are inflected forms of “be”?


{kind=link}
{kind=link}
{kind=link}
2 Comments
Can I get this Lemmatizer API freely…. how can i get this and how can i apply this API to my own program. Please help me regarding this…( i just tried Lemmatization with R but i didn’t got desiedred output
Hi @BHANUMATHIHM, you can try out the Lemmatizer API on the demo page. There you can see how it works and an explanation of how each option controls the output. You can also check out this post about controlling the output.
Our APIs are listed on the Mashape API Marketplace and are RESTful APIs. This Lemmatizer API is free so all you have to do is just sign up on Mashape to get your free API key and the endpoint info. Please feel free to comment again if you have any questions. You can also email us at [email protected] if you need more specific help.
Good luck!