We decided to focus more on other products due to ecosystem of API and machine learning. Please contact us to get more support. Thank you!
Have trouble subscribing to our inference models on AWS Sagemaker? Not sure how to run a batch transform job? No worries, this post explains how to do both, and gives you input and output sample data as well. Click the links below to skip ahead:
How to subscribe to Twinword’s inference models
How to run a batch transform job
Subscribe To Twinword’s Inference Models On AWS Sagemaker
1. Subscribe To Model Package
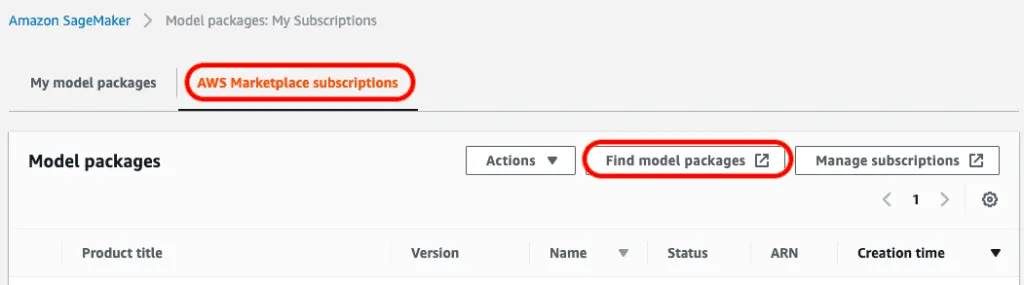
In the AWS Sagemaker console, find ‘Inference’ in the menu on the left side and click ‘Model packages’.

Next, in the AWS Marketplace subscriptions tab, click on ‘Find model packages’.
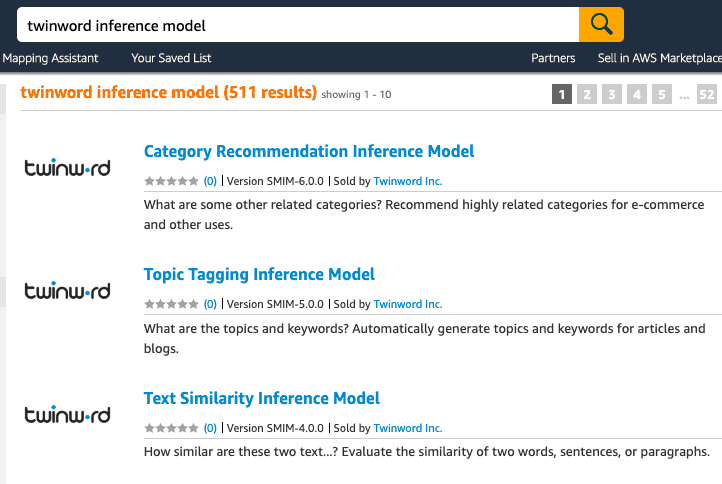
Here you can search for Twinword’s inference models. Simply search for ‘twinword inference model’ and select the inference model of your choice.
One you selected an inference model, click on ‘continue to subscribe’.

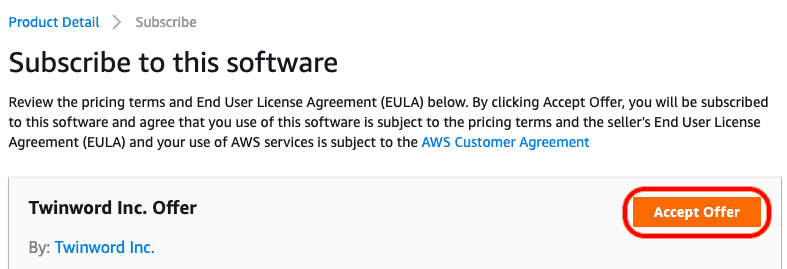
Afterwards, click on ‘Accept offer’.
2. Create A Model
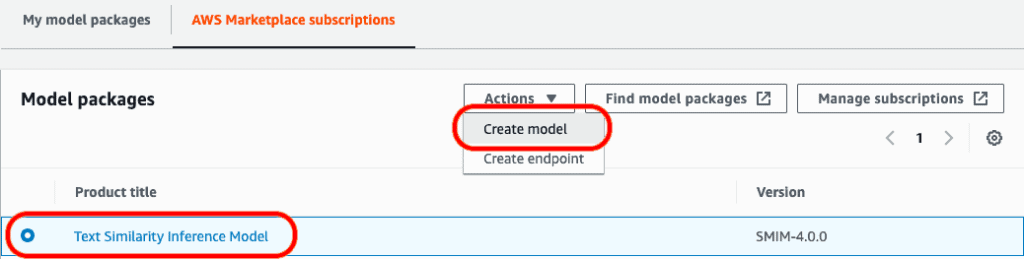
Now, that you’ve successfully subscribed, go back to your Sagemaker console. The model packages you subscribed to should now appear under ‘AWS Marketplace subscription list’.
Select an inference model, and under ‘actions’, click ‘create a model’.
Next, type in a custom model name and click ‘Create a new role’ under IAM role.
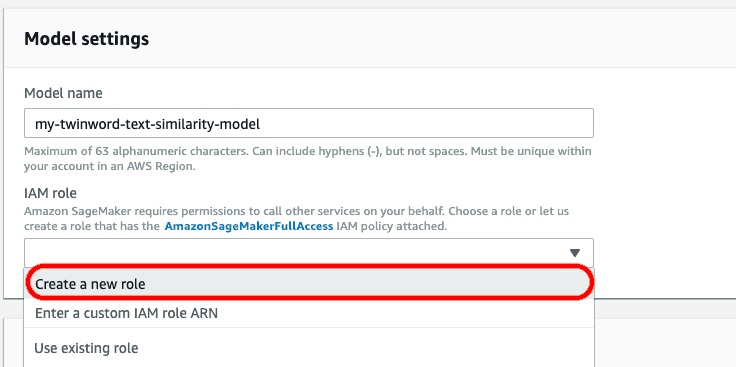
A pop-up will open. Select a specific S3 bucket or ‘Any S3 bucket’, and click ‘Create role’.
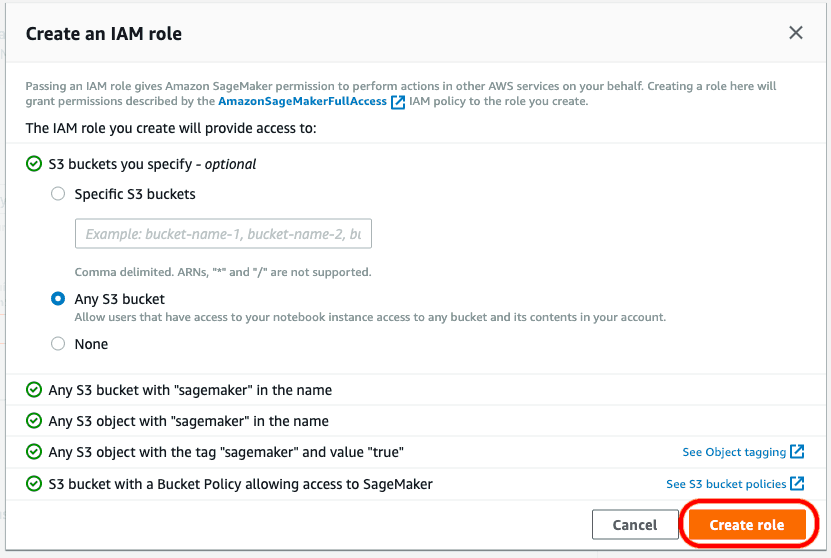
Next, in the Container definition 1 field, make sure that ‘Use a model package subscription from AWS Marketplace’ is selected.
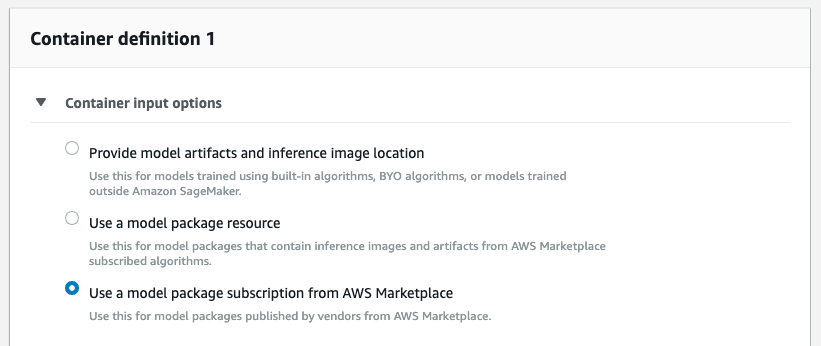
Leave the rest as it is and click ‘Create model’ at the end of the page. Now you have created a model using the subscribed model package, great!
Run A Batch Transform Job
Currently, our inference models can only be used with batch transform jobs (not as Endpoints). Find out below how to run a batch transform job.
1. Upload Input Data Into S3 Bucket
Each request needs to be stored and uploaded in a separate file. Twinword’s inference models require either plain text or JSON as an input format depending on the model. Find input samples for each inference model.
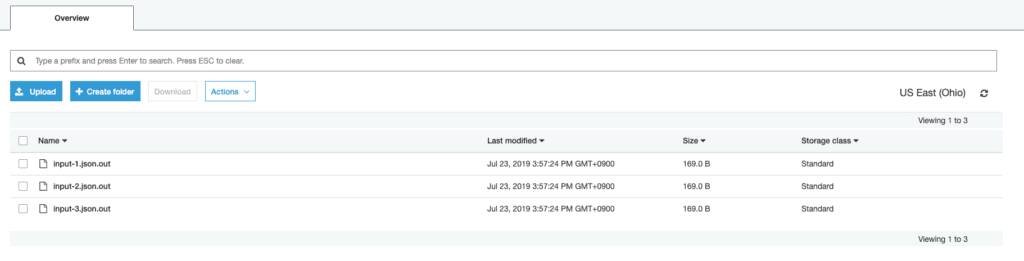
After you uploaded your input files you can start the batch transform job.
2. Create The Batch Transform Job
In the left side menu, click ‘Batch transform jobs’.

Then, click ‘Create batch transform job’.

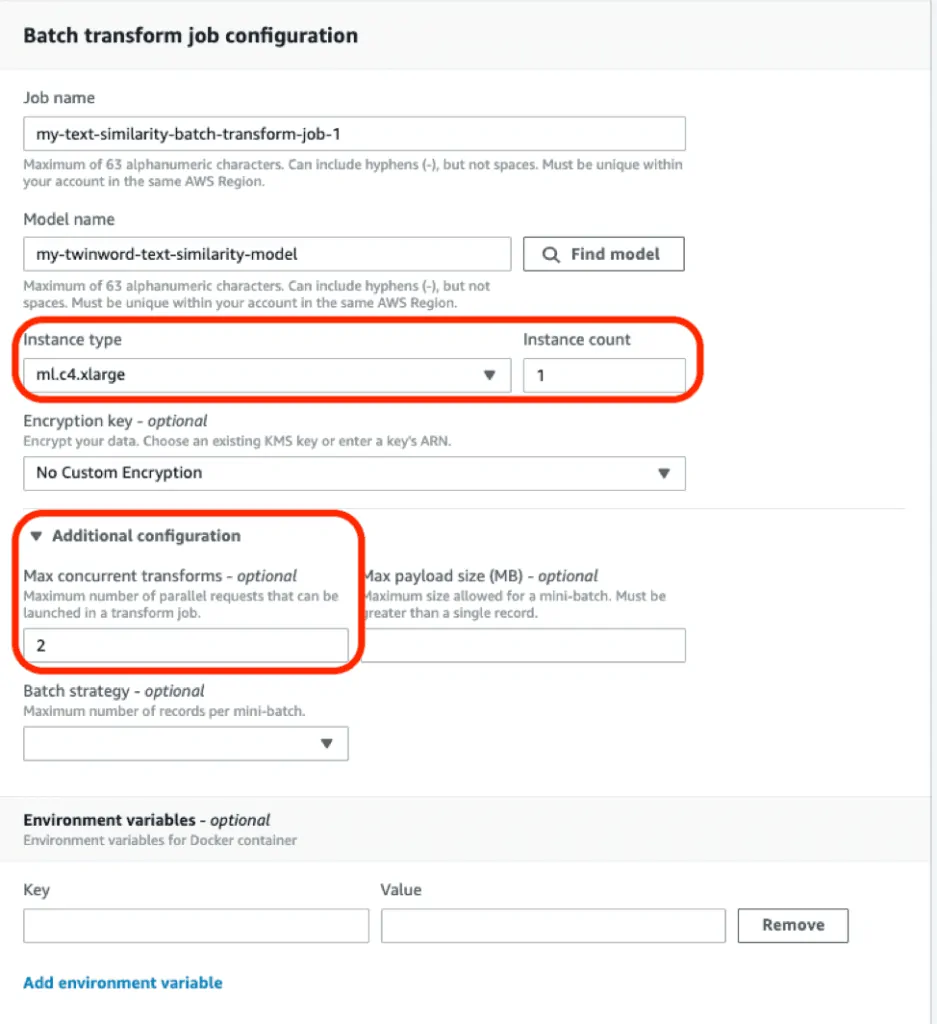
Batch Transform Job Configuration
In the Batch transform job configuration, fill in the ‘Job name’ and find the model you just created by clicking on ‘Find model’, Afterwards, select the Instance type and Instance count that you want.
Next, open ‘Additional configuration’ and set the desired maximum concurrent transforms. The bigger your instance type and instance count, the more maximum concurrent transforms are possible. However, the maximum amount is also influenced by input data size.
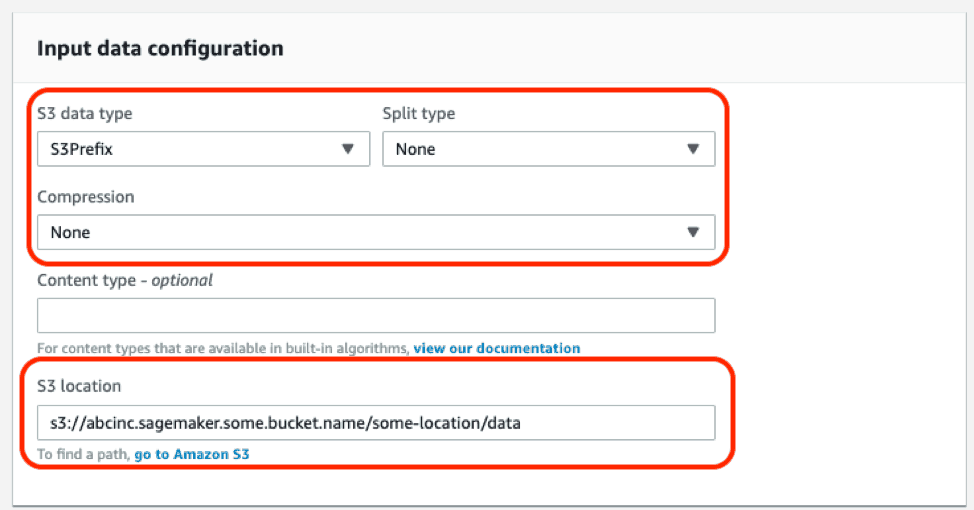
Input Data Configuration
For the input data configuration field, select ‘S3 Prefix’ as your S3 data type, and select ‘None’ for the Split type. For Compression, select ‘None’, and under S3 location, make sure to specify your S3 location where you uploaded your input files earlier.
Output Data Configuration
In the Output data configuration field, specify your S3 output path and leave the rest as it is. 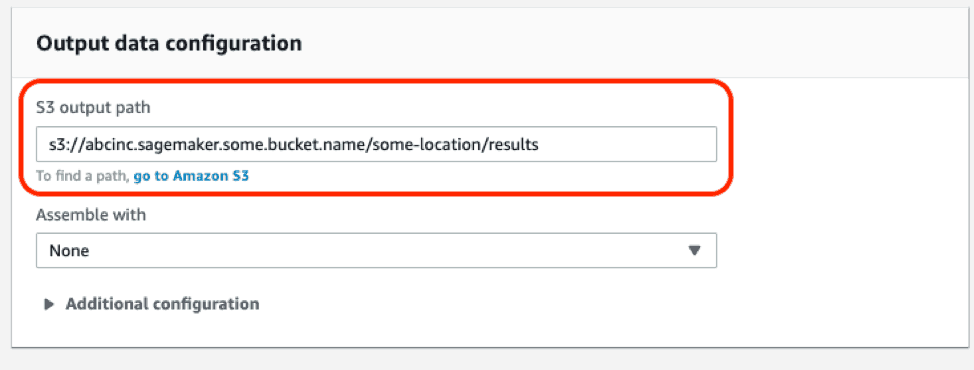
Now, leave everything else the way it is and click ‘Create job’ at the end of the page. After the job is created, you’ll see the batch transform job listed under Batch transform jobs. You should see that its status is ‘In Progress’.

If you click on the job you can get more details, or you can stop the job. Once the status is ‘Completed’, you should be able to find your results in the S3 location you specified for the output path.
And that’s it, you’re done!
Input and Output Samples
The input format for Twinword’s inference models is either plain text or JSON depending on the model. The output format is JSON.
Sentiment Analysis Inference Model
Input format: Text
Input sample: great value in its price range!
Output sample: {
“type”: “positive”,
“score”: 0.375758241,
“ratio”: 1,
“keywords”: [
{
“word”: “great”,
“score”: 0.797954407
},
{
“word”: “price”,
“score”: 0.289701948
},
{
“word”: “value”,
“score”: 0.263316882
},
{
“word”: “range”,
“score”: 0.152059727
}
],
“version”: “4.0.0”,
“author”: “twinword inc.”,
“email”: “[email protected]”,
“result_code”: “200”,
“result_msg”: “Success”
}
Emotion Analysis Inference Model
Input format: Text
Input sample: After living abroad for such a long time, seeing my family was the best present I could have ever wished for.
Output sample: {
“emotions_detected”: [
“joy”
],
“emotion_scores”: {
“joy”: 0.13447999002654,
“sadness”: 0.022660050917593,
“surprise”: 0.0087308825457527,
“fear”: 0,
“anger”: 0,
“disgust”: 0
},
“version”: “7.0.0”,
“author”: “twinword inc.”,
“email”: “[email protected]”,
“result_code”: “200”,
“result_msg”: “Success”
}
Topic Tagging Inference Model
Input format: Text
Input sample: Computer science is the scientific and practical approach to computation and its applications. It is the systematic study of the feasibility, structure, expression, and mechanization of the methodical procedures (or algorithms) that underlie the acquisition, representation, processing, storage, communication of, and access to information, whether such information is encoded as bits in a computer memory or transcribed in genes and protein structures in a biological cell. An alternate, more succinct definition of computer science is the study of automating algorithmic processes that scale. A computer scientist specializes in the theory of computation and the design of computational systems.
Output sample: {
“keyword”: {
“computer”: 4,
“compute”: 2,
“structure”: 2,
“information”: 2,
“study”: 2,
“science”: 2,
“cell”: 1,
“alternate”: 1,
“biological”: 1,
“gene”: 1
},
“topic”: {
“computer science”: 0.5010800744879,
“study”: 0.30018621973929,
“human”: 0.23091247672253,
“machine”: 0.23091247672253,
“system”: 0.23091247672253,
“art”: 0.20782122905028,
“technology”: 0.18472998137803,
“development”: 0.18472998137803,
“number”: 0.18472998137803
},
“version”: “5.0.0”,
“author”: “twinword inc.”,
“email”: “[email protected]”,
“result_code”: “200”,
“result_msg”: “Success”
}
Category Recommendation Inference Model
Input format: Text
Input sample: coffee maker
Output sample: {
“keywords”: [
“maker”,
“coffee”
],
“categories”: [
“Coffee Maker Water Filters”,
“Coffee Decanters”,
“Coffee Filters”,
“Coffee Maker & Espresso Machine Accessories”,
“Coffee Filter Baskets”,
“Coffee Decanter Warmers”,
“Frothing Pitchers”,
“Stovetop Espresso Pot Parts”,
“Coffee”,
“Coffee Pods”
],
“keywords_scored”: {
“maker”: 1,
“coffee”: 1
},
“categories_scored”: {
“Coffee Maker Water Filters”: 1,
“Coffee Decanters”: 1,
“Coffee Filters”: 1,
“Coffee Maker & Espresso Machine Accessories”: 1,
“Coffee Filter Baskets”: 1,
“Coffee Decanter Warmers”: 1,
“Frothing Pitchers”: 1,
“Stovetop Espresso Pot Parts”: 1,
“Coffee”: 1,
“Coffee Pods”: 1
},
“taxonomy_set”: “product_categories”,
“version”: “6.0.0”,
“author”: “twinword inc.”,
“email”: “[email protected]”,
“result_code”: “200”,
“result_msg”: “Success”
}
Lemmatizer Inference Model
Input format: JSON
Input sample: {“text”:”The frogs hopped from rock to rock.”,”flag”:”VALID_TOKENS_ONLY_ORDER_BY_OCCURRENCE_SHOW_COUNT”,”exclude_non_content_words”:0}
Output sample: {
“lemma”: {
“rock”: 2,
“frog”: 1,
“hop”: 1
},
“version”: “4.0.0”,
“author”: “twinword inc.”,
“email”: “[email protected]”,
“result_code”: “200”,
“result_msg”: “Success”
}
Language Scoring Inference Model
Input format: Text
Input sample: The hippocampus is a major component of the brains of humans and other vertebrates. It belongs to the limbic system and plays important roles in the consolidation of information from short-term memory to long-term memory and spatial navigation. Humans and other mammals have two hippocampi, one in each side of the brain. The hippocampus is a part of the cerebral cortex; and in primates it is located in the medial temporal lobe, underneath the cortical surface. It contains two main interlocking parts: Ammon’s horn and the dentate gyrus.
Output sample: {
“ten_degree”: 6,
“value”: 0.18788740723541,
“version”: “5.0.0”,
“author”: “twinword inc.”,
“email”: “[email protected]”,
“result_code”: “200”,
“result_msg”: “Success”
}
Text Similarity Inference Model
Input format: JSON
Input sample: {“text1″:”you had me at hello”,”text2″:”you had me at goodbye”}
Output sample: {
“similarity”: 0.22480382541794,
“value”: 44960.765083588,
“version”: “4.0.0”,
“author”: “twinword inc.”,
“email”: “[email protected]”,
“result_code”: “200”,
“result_msg”: “Success”
}
Word Associations Inference Model
Input format: Text
Input sample: sound
Output sample: {
“entry”: “sound”,
“request”: “sound”,
“response”: {
“sound”: 1
},
“associations”: “noise, voice, loud, din, growl, acoustic, resounding, whisper, roar, bell, hiss, hearing, music, echo, shout, speak, tone, hear, sing, vocal, radio, bang, ring, scream, song, talk, angry, quiet, language, say”,
“associations_array”: [
“noise”,
“voice”,
“loud”,
“din”,
“growl”,
“acoustic”,
“resounding”,
“whisper”,
“roar”,
“bell”,
“hiss”,
“hearing”,
“music”,
“echo”,
“shout”,
“speak”,
“tone”,
“hear”,
“sing”,
“vocal”,
“radio”,
“bang”,
“ring”,
“scream”,
“song”,
“talk”,
“angry”,
“quiet”,
“language”,
“say”
],
“associations_scored”: {
“noise”: 0.87924904,
“voice”: 0.69780004,
“loud”: 0.64684,
“din”: 0.328791,
“growl”: 0.32570618,
“acoustic”: 0.29006705,
“resounding”: 0.27822074,
“whisper”: 0.27312076,
“roar”: 0.26633215,
“bell”: 0.25933203,
“hiss”: 0.25909933,
“hearing”: 0.24920546,
“music”: 0.24438183,
“echo”: 0.22831623,
“shout”: 0.22262712,
“speak”: 0.22007167,
“tone”: 0.2196229,
“hear”: 0.21679422,
“sing”: 0.19944496,
“vocal”: 0.19469869,
“radio”: 0.17033531,
“bang”: 0.17011541,
“ring”: 0.16973364,
“scream”: 0.16852735,
“song”: 0.14971475,
“talk”: 0.14550306,
“angry”: 0.14197367,
“quiet”: 0.12710004,
“language”: 0.1247648,
“say”: 0.11698033
},
“version”: “4.0.0”,
“author”: “twinword inc.”,
“email”: “[email protected]”,
“result_code”: “200”,
“result_msg”: “Success”
}



{kind=link}
{kind=link}
{kind=link}