Before we even start describing the concept of typoglycemia, take a look at this numerical puzzle, that makes hundreds of people online loose their minds:
 Source: http://www.storypick.com/number-puzzle-lose-your-mind/
Source: http://www.storypick.com/number-puzzle-lose-your-mind/
Found it?
Number 4 looks quite suspicious, isn’t it?
Well, if you give a chance for your brain to focus on the actual task of the puzzle, you will see immediately “MITSAKE”.
According to Wikipedia, Typoglycemia is a neologism given to a purported recent discovery about the cognitive processes behind reading written text. The theory behind claims that the human mind does not read every letter of every word or decipher each word separately in a sentence. In fact, the human brain reads base on past experience and cognitive knowledge. You’ve probably have seen the below:

Now isn’t that amazing?
“Cognitive abilities are brain-based skills we need to carry out any task from the simplest to the most complex. They have more to do with the mechanisms of how we learn, remember, problem-solve, and pay attention rather than with any actual knowledge.” (Sharpbrains.com)
So, it makes me wonder, if we are able to read scrambled words that easily, what about reading an article with lemmatized words? English words appear in several inflected forms, the verb ‘to talk’ may appear as ‘talk’, ‘talks’, ‘talked’, ‘talking’. The root form, ‘talk’, is known as the lemma for the word. To test it out, I put an article through our Lemmatizer API and this is what I got:
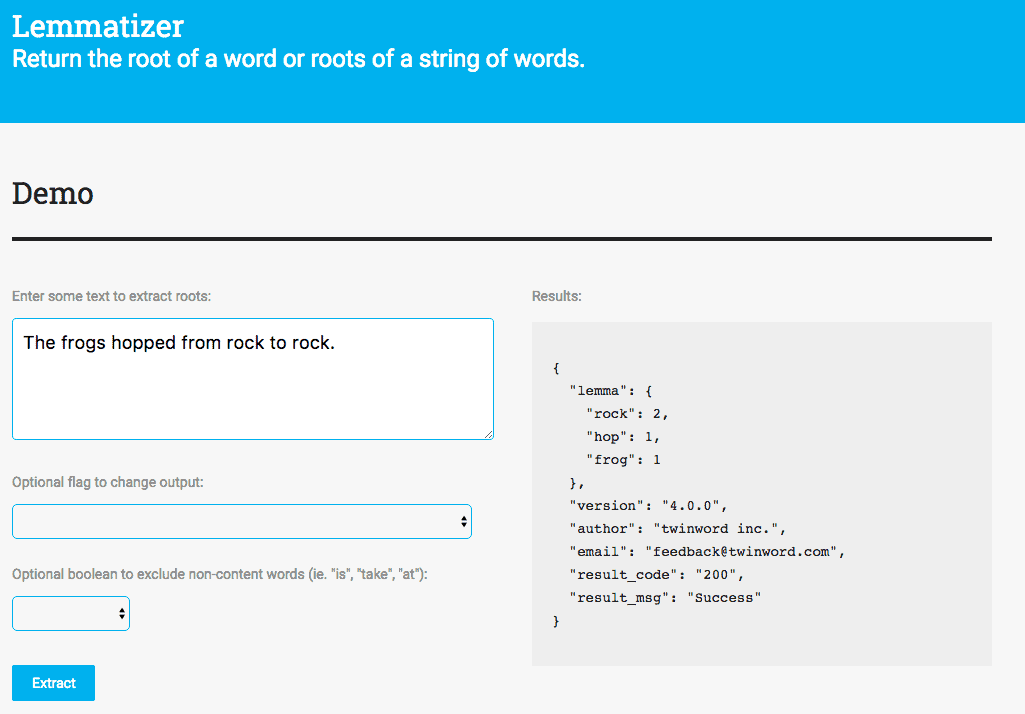
Well in conclusion, the lemmatized extract was not unreadable, but it sure is enough to make all English teachers cringe! Why wouldn’t you try to come up with lemmatized text with this Lemmatizer API?


{kind=link}
{kind=link}